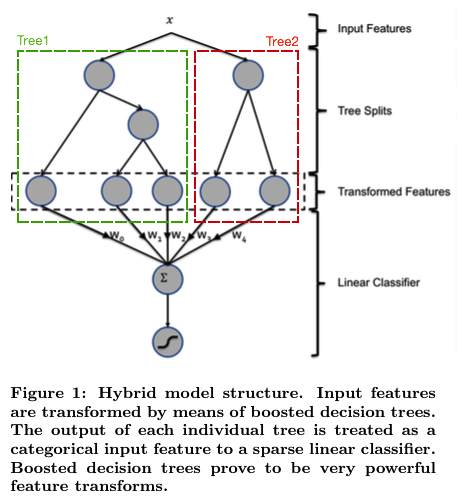
就是先用已有特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,最后把这些新特征加入原有特征一起训练模型。构造的新特征向量是取值0/1的,向量的每个元素对应于GBDT模型中树的叶子结点。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于GBDT模型里所有树包含的叶子结点数之和。
举例说明。下面的图中的两棵树是GBDT学习到的,第一棵树有3个叶子结点,而第二棵树有2个叶子节点。对于一个输入样本点x,如果它在第一棵树最后落在其中的第二个叶子结点,而在第二棵树里最后落在其中的第一个叶子结点。那么通过GBDT获得的新特征向量为[0, 1, 0, 1, 0],其中向量中的前三位对应第一棵树的3个叶子结点,后两位对应第二棵树的2个叶子结点。
附录
特征交叉的方法:
做点击率预估需要两方面的数据,一方面是广告的数据,另一方面是用户的数据,现在所有的数据都有,那么工作就是利用这两方面的数据评估用户点击这个广告的可能性(也就是概率)。用户的特征是比较多的,用户的年龄,性别,地域,职业,学校,手机平台等等。广告的特征也很丰富,如广告大小,广告文本,广告所属行业,广告图片。还有反馈特征,如每个广告的实时ctr,广告跟性别交叉的ctr。如何从这么多的特征中选择到能刻画一个人对一个广告的兴趣的特征,是数据挖掘工程师的一个大难题。
交叉从理论上而言是为了引入特征之间的交互,也即为了引入非线性性。是有实际意义的。本文对交叉的意义解释得非常nice。